内存管理、磁盘和文件拾遗
Part1. 内存管理
一个程序的可执行文件在内存中的结果,从大的角度可以分为两个部分:只读部分和可读写部分。只读部分包括程序代码(.text)和程序中的常量(.rodata)。
可读写部分(变量)大致可分为下面几个部分:
.data:初始化了的全局变量和静态变量.bss:即Block Started by Symbol,未初始化的全局变量和静态变量heap:堆,使用malloc、realloc和free函数控制的变量,堆在所有的线程,共享库,和动态加载的模块中被共享使用。stack:栈,函数调用时使用栈来保存函数现场,自动变量(即生命周期限制在某个 scope 的变量)也存放在栈中。
1. .data 和 .bss 区
这两个经常放在一起说,因为他们都是用来存储全局变量和静态变量的,区别在于 .data 区存放的初始化过的,.bss区存放的是没有初始化过的。例如:
int val = 3;
char string[] = 'Hello World';
这两个变量的值会在一开始被存储在 .text 中,因为值是写在代码里面的,在程序启动时会拷贝到 .data 区中。
若不初始化,类似:
static int i;
这个变量就会被放在 .bss 区中。
静态变量和全局变量
全局变量
在一个代码文件中,一个变量要么定义在函数中,要么定义在函数外。当定义在函数外时,这个变量就有了全局作用域,成为了全局变量。
全局变量不光意味着这个变量可以在整个文件中使用,也意味着这个变量可以在其他文件中使用(这种叫 external linkage)。
当有如下两个文件时:
A.c
#include <stdio.h>
int a;
int compute(void);
int main()
{
a = 1;
printf("%d %d", a, compute());
return 0;
}
B.c
int a;
int compute(void)
{
a = 0;
return a;
}
在编译过程中会产生重复定义的错误!因为有两个全局的 a 变量,编译器不知道应该使用哪一个,为了避免这种问题,就需要引入 static。
静态变量
使用 static 关键字修饰的变量,static 关键字对变量的作用域进行了限制,具体的限制如下:
- 在函数外定义:全局变量,但是只在当前文件中可见(叫做 internal linkage)。
- 在函数内定义:全局变量,但是只在此函数内可见(同时,在多次函数调用中,变量的值不会丢失)。
C++在类中定义:全局变量,但是只在此类中可见
对于全局变量来说,为了避免上面提到的重复定义错误,我们可以在一个文件中使用 static,另一个不使用,这样使用 static 的就会使用自己的 a 变量,而没有用 static 的会使用全局的 a 变量。
注意:静态这个中文翻译有点莫名其妙,给人的感觉像是不可改变的,实际上static 跟不可改变没有关系,不可改变的变量使用 const 关键字修饰!!!
extern
extern 是 C 语言的另一个关键字,用来指示变量或函数的定义在别的文件中,使用 extern 可以在多个源文件中共享某个变量。
程序在内存和硬盘上不同的存在形式
这里提到的四个区,是指程序在内存中存在的形式,和程序在硬盘上存储的格式不是完全对应的。程序在硬盘上存储的格式更加复杂,而且是和操作系统有关的,具体可以参考:wikipedia。
一个明显的例子区分这个差别:
之前提到的未定义的全局变量存储在 .bss 区,这个区域不会占用可执行文件的空间(一般只存储这个区域的长度),但是却会占用内存空间。这些变量没有定义,因此可执行文件中不需要存储他们的值,在程序启动过程中,他们的值会被初始化成 0,存储在内存中。
2. 栈
栈是用于存放本地变量,内部临时变量以及有关上下文的内存区域。程序在调用函数时,操作系统会自动通过压栈和弹栈完成保存函数现场等操作,不需要程序员手动干预。
栈是一块连续的内存区域,栈顶的地址和栈的最大容量是系统预先规定好的,能从栈获得的空间较小。如果申请的空间超过栈的剩余空间时,例如递归深度过深,将提示:stackoverflow。
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈、出栈都有专门的指令执行,这就决定了栈的效率比较高。
3. 堆
堆是用于存放除了栈里的东西之外所有其他东西的内存区域,当使用 malloc 和 free 时就是在操作堆中的内存。对于堆来说,释放工作由程序员控制,容易产生 memory leak。
堆是向高地址扩展的数据结构,是不连续的内存区域。这里由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
对于堆而言,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈而言,则不会出现这个问题,因为栈是先进后出的队列,永远都不可能有一个内存块从栈中间弹出。
堆都是动态分配的,没有静态分配的堆。栈有两种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 alloca 函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
计算机底层并没有对堆的支持,堆则是 C/C++ 函数库提供的,同时由于上面提到的碎片问题,都会导致堆的效率比栈要低。
Part.2 内存分配
- 虚拟地址:用户编译时将代码(或数据)分成若干个段,每条代码或每个数据的地址由段名称 + 段内相对地址构成,这样的程序地址称为虚拟地址。
- 逻辑地址:虚拟地址中,段内相对地址部分称为逻辑地址。
- 物理地址:实际物理内存中所看到的存储地址称为物理地址。
- 逻辑地址空间:在实际应用中,将虚拟地址和逻辑地址经常不加以区分,通称为逻辑地址,逻辑地址的几个称为逻辑地址空间。
- 线性地址空间:CPU 地址总线可以访问的所有地址合称为线性地址空间。
- 物理地址空间:实际存在的可访问的物理内存地址集合称为物理地址空间。
- MMU(Memery Management Unit)内存管理单元:实现将用户程序的虚拟地址(逻辑地址)-> 物理地址映射的 CPU 中的硬件电路。
- 基地址:在进行地址映射时,经常以段或页为单位并以其最小地址(即起始地址)为基值来进行计算。
- 偏移量:在以段或页为单位进行地址映射时,相对于基地址的地址值。
虚拟地址先经过分段机制映射到线性地址,然后线性地址通过分页机制映射到物理地址。
Part.3 虚拟内存
请求调页
也成为按需调页,即对不在内存中的“页”,当进程执行时才调入,否则有可能到程序结束时也不会调入。
页面置换算法
-
FIFO 算法
先入先出,即淘汰最早调入的页面。 -
OPT(MIN) 算法
选未来最远将使用的页淘汰,是一种最优的方案,可以证明缺页数最小。
可惜,MIN 需要知道将来发生的事,只能在理论中存在,实际不可应用。 -
LRU(Least-Recently-Used) 算法
用过去的历史预测将来,选最近最长时间没有使用的页淘汰(也称最近最少使用)。LRU 准确实现:计数器法,页码栈法。由于代价较高,通常不使用准确实现,而是采用近似实现,例如Clock算法。
内存抖动
页面的频繁更换,导致整个系统效率急剧下降,这个现象称为内存抖动(或颠簸)。
抖动一般是内存分配算法不好,内存太小引起或者程序的算法不佳引起的。
Belady 现象
对有的页面置换算法,页错误率可能会随着分配帧数的增加而增加。
FIFO 会产生 Belady 异常。
栈式算法无 Belady 异常,LRU、LFU(最不经常使用)、OPT 都属于栈式算法。
Part.4 磁盘调度
磁盘访问延迟 = 队列时间 + 控制器时间 + 寻道时间 + 旋转时间 + 传输时间。
磁盘调度的目的是减小延迟,其中前两项可以忽略,寻道时间是主要矛盾。
磁盘调度算法
-
FCFS
先进先出的调度策略,这个策略具有公平的优点,因为每个请求都会得到处理,并且是按照接收到的顺序进行处理。 -
SSTF(Shortest-seek-time 最短寻道时间优先)
选择使磁头从当前位置开始移动最少的磁盘 I/O 请求,所以 SSTF 总是选择导致最小寻道时间的请求。
总是选择最小寻找时间并不能保证平均寻找时间最小,但是能提供比 FCFS 算法更好的性能,会存在饥饿现象。 -
SCAN
SSTF + 中途不回折,每个请求都有处理机会。
SCAN 要求磁头仅仅沿一个方向移动,并在途中满足所有未完成的请求,直到它到达这个方向上的最后一个磁道,或者在这个方向上没有其他请求为止。
由于磁头移动规律与电梯运行相似,SCAN 也被称为电梯算法。
SCAN 算法对最近扫描过的区域不公平,因此,它的访问局部性方面不如 FCFS 算法和 SSTF 算法好。 -
C-SCAN
SCAN + 直接移到另一端,两端请求都能很快处理。
把扫描限定在一个方向,当访问到某个方向的最后一个磁道时,磁道返回磁盘相反方向磁道的末端,并再次开始扫描。
其中 “C” 是Circular(环)的意思。 -
LOOK 和 C-LOOK
采用 SCAN 算法和 C-SCAN 算法时磁头总是严格地遵循从盘面的一端到另一端,显然,在实际使用时还可以改进,即磁头移动只需要到达最远端的一个请求即可返回,不需要到达磁盘端点。这种形式的 SCAN 算法和 C-SCAN 算法称为 LOOK 和 C-LOOK 调度。这是因为它们在朝一个给定方向移动前会查看是否有请求。
Part5. 文件系统
分区表
- MBR:支持最大卷为 2TB(Terabytes),并且每个磁盘最多有 4 个主分区(或 3 个主分区、1 个扩展分区和无限制的逻辑驱动器)
- GPT:支持最大卷为 18EB(Exabytes),并且每磁盘的分区数没有上限,只受到操作系统限制,由于分区表本身需要占用一定空间,最初规划硬盘分区时,留给分区表的空间决定了最多可以有多少个分区,IA-64版 Windows 限制最多有 128 个分区,这也是 EFI 标准规定的分区表的最小尺寸。另外 GPT 分区磁盘有备份分区表来提高分区数据结构的完整性。
RAID 技术
独立硬盘冗余阵列(RAID, Redundant Array of Independent Disks),旧称廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks),简称磁盘阵列。利用虚拟化存储技术把多个硬盘组合起来,成为一个或多个硬盘阵列组,目的为提升性能或数据冗余,或是两者同时提升。
在运作中,取决于 RAID 层级不同,数据会以多种模式分散于各个硬盘,RAID 层级的命名会以 RAID 开头并带数字,例如:RAID 0、RAID 1、RAID 5、RAID 6、RAID 7、RAID 01、RAID 10、RAID 50、RAID 60。每种等级都有其理论上的优缺点,不同的等级在两个目标间获取平衡,分别是增加数据可靠性以及增加存储器(群)读写性能。
-
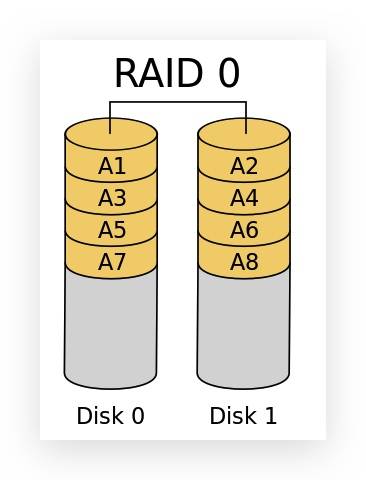
RAID 0
RAID 0 是最早出现的 RAID 模式,需要两块以上的硬盘,可以提高整个磁盘的性能和吞吐量。
RAID 0 没有提供冗余或错误修复能力,其中一块硬盘损坏,所有的数据将遗失。
-
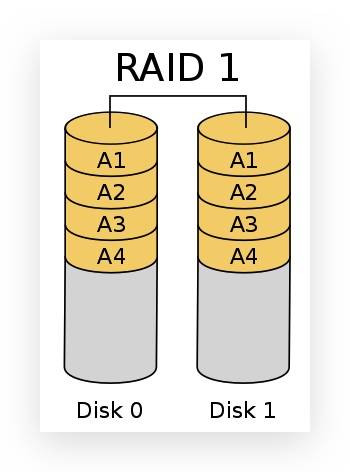
RAID 1
RAID 1 就是镜像,其原理为在主硬盘上存放数据的同时也在镜像硬盘上写一样的数据,当主硬盘(物理)损坏时,镜像硬盘则代替主硬盘的工作。因为有镜像硬盘做数据备份,所以 RAID 1 的数据安全性在所有 RAID 级别上来说是最好的。
但无论用多少磁盘做 RAID 1,仅算一个磁盘的容量,是所有 RAID 中磁盘利用率最低的。
实际容量:Size = min(S1, S2, S3 ... Sn)
-
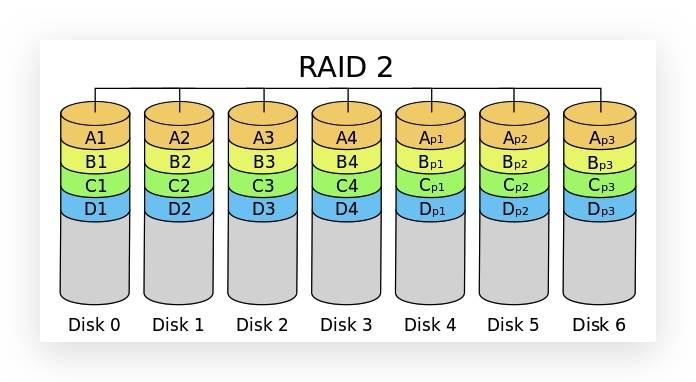
RAID 2
这是 RAID 0 的改良版,以汉明码(Hamming Code)的方式将数据进行编码后分区为独立的比特,并将数据分别写入硬盘中。因为在数据中加入了错误修正码(ECC,Error Correction Code),所以数据整体的容量会比原始数据大一些,RAID 2 至少需要三台磁盘驱动器方能运作。
-
RAID 3
采用 Bit-interleaving(数据交错存储)技术,它需要通过编码再将数据比特分割后分别存在磁盘中,而将同比特检查后单独存在一个硬盘中,但由于数据内的比特分散在不同的硬盘上,因此就算要读取一小段数据资料都可能需要所有的硬盘进行工作,所以这种规格比较适用于读取大量数据时使用。
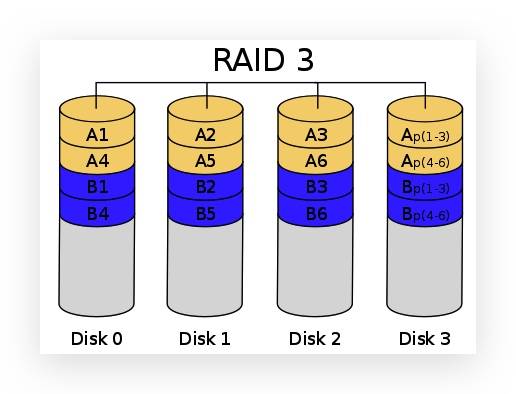
-
RAID 4
它与 RAID 3 不同的是它在分区时是以区块为单位分别存在硬盘中,但每次的数据访问都必须从同比特检查的那个硬盘中取出对应的同比特数据进行核对,由于过于频繁的使用,所以对硬盘的损耗可能会提高。(快交织技术,Block interleaving)。
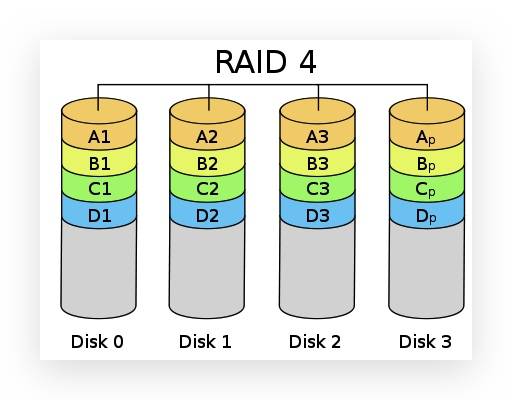
RAID 2、3、4 在实际应用中很少使用
-
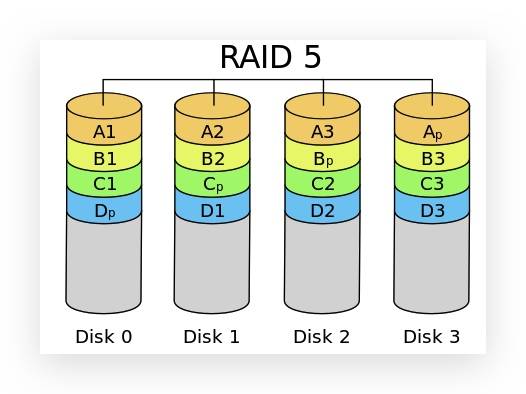
RAID 5
RAID Level 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案,他使用的是 Disk Striping(硬盘分区)技术。
RAID 5 至少需要三块硬盘,RAID 5 不是对存储的数据进行备份,而是把数据和相对应的数据分别存储于不同的磁盘上。
RAID 5 允许一块硬盘损坏。
实际容量:Size = (N - 1) * min(S1, S2, S3... SN)
-
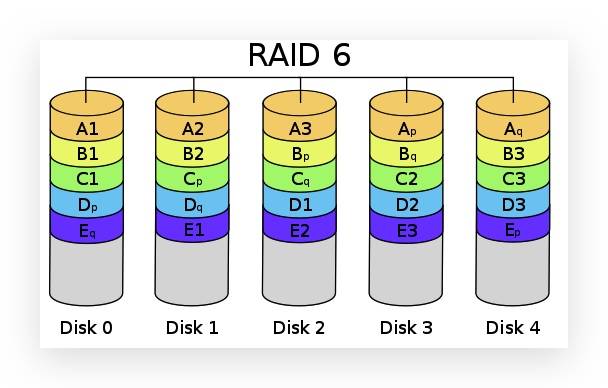
RAID 6
与 RAID 5 相比,RAID 6 增加第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。
RAID 6 至少需要 4 块硬盘。
实际容量:Size = (N - 2) * min(S1, S2, S3 ... SN)
-
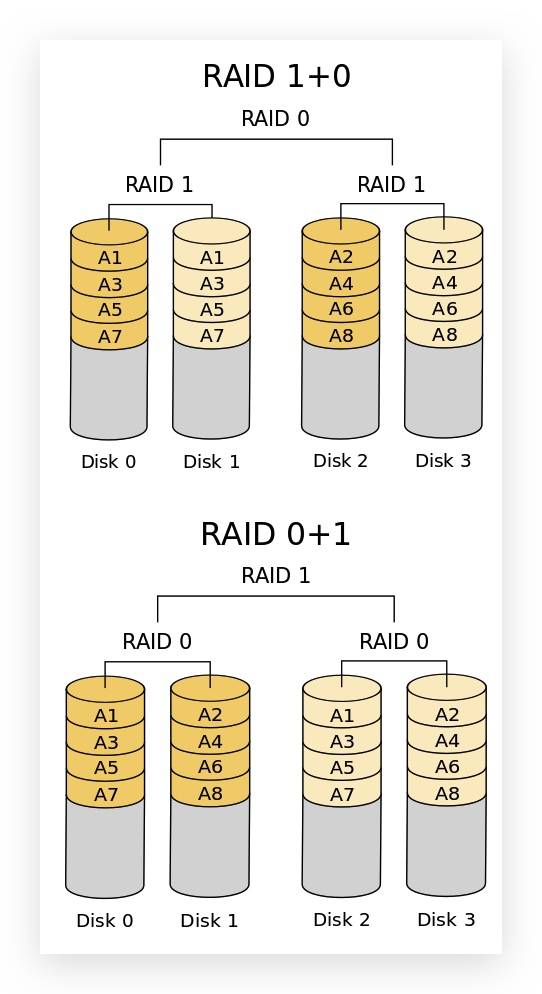
RAID 10/01 (RAID 1 + 0, RAID 0 + 1)
RAID 10 是先镜射再分区数据,再将所有硬盘分为两组,视为是 RAID 0 的最低组合,然后将这两组各自视为 RAID 1 运作。
RAID 01 则是跟 RAID 10 的程序相反,是先分区再将数据镜射到两组硬盘。它将所有的硬盘分为两组,变成 RAID 1 的最低组合,而将两组硬盘各自视为 RAID 0 运作。
当 RAID 10 有一个硬盘受损,其余硬盘会继续运作,RAID 01 只要有一个硬盘受损,同组 RAID 0 的所有硬盘都会停止运作,只剩下其他组的硬盘运作,可靠性较低。
如果以 6 个硬盘建 RAID 01,镜射再用三个建 RAID 0,那么坏一个硬盘便会有三个硬盘脱机,因此,RAID 10 远比 RAID 01 常用,零售主板绝大多数支持 RAID 0/1/5/10, 但不支持 RAID 01.
RAID 10 至少需要 4 块硬盘,且硬盘数量必须为偶数。
常见的文件系统
- Windows:FAT,FAT16,FAT32,NTFS
- Linux:ext2/3/4,btrfs,ZFS
- Mac OS X:HFS+
更多干货文章
博客:www.qiuxuewei.com
微信公众号:@开发者成长之路

一个没有鸡汤只有干货的公众号